Back • Return Home
Web Development Basics
We already spoke a little bit about the basics behind computers and programming. [You might want to read that one first.] Now, let's cover The Internet and The Web! This might seem like a lot of "jargon". Please have patience for it.
Contents
• What Is The Internet & How Does It Work?
• How Do We Make Stuff For The Web?
• What Do We Do With These Files?
How Do We Rent A Server?
How Do We Build & Maintain A Server?
What Can We Do With A Server & A Client?
• What Is Cybersecurity?
Safety In Web Surfing
Protecting Our Personal Website
Running Our Own Social Network?
What Is The Internet & How Does It Work?
There are many simple and straightforward explanations of what "The Internet" is (such as the works of Brian Will and Ernie Dainow). We will try to reiterate a few of those concepts here...
Individual computers can be linked together to form a Local Area Network (or LAN). The computers within this Network can be connected directly with cables (such as in the case of "Ethernet"), or with radio signals that are sent and received through antennas (such as in the case of "Wi-Fi"). The Network is considered "local" because the area that it covers on Earth is limited in range.
Within the context of a Network, each computer is generally referred to as a Host. They are connected together with a device called a Network Switch. Every physical device has a Network Interface Card (or NIC) inside of it. Each NIC has a Media Access Controller Address (or MAC Address) that is unique to that device alone. This is how the Network Switch differentiates between everything that is connected together within the same LAN.
Two Networks can also be connected together through a device named a Router (so-called because it "routes" information between Networks). A single Network is known as an Intranet, while a collection of them is an Extranet. A Network of Networks can be thought of as essentially one larger Network that covers a wider area. For this reason, it is also referred to as a Wide Area Network (or WAN). A WAN is multiple LANs that can communicate with one another.
The collection of all Networks interconnected together across the entire world is referred to as The Internet. When an individual wants to access The Internet, they usually connect their computer to it through an organization called an Internet Service Provider (or ISP). Devices that are connected to The Internet are "online", while devices that are not connected to it are "offline".
Whether on an Intranet or The Internet, one computer is being used to send a "request" for data from another. The computer making the "request" is called a Client and the computer that gives the data in "response" is called a Server.
A standard way in which multiple computers can send and receive data from each other is referred to as a Protocol. There are many different Protocols, but one of the most common is known as Transmission Control Protocol (or TCP for short). It splits up the data that is to be sent into little chunks called Packets.
Then, another Protocol called Internet Protocol (or IP) is used to make sure that those Packets are sent to the right computer. This is possible because the location of every computer within a Network is specified by a unique string of numbers referred to as an "IP Address".
Overlaid on top of this system is another Protocol named HyperText Transfer Protocol (or HTTP). A "Hypertext" is simply a type of document (also known as a Webpage) that can connect to other documents through special "Hyperlinks" within it. A Server can then hold a collection of these Webpages (i.e.: a Website), and a Client can view them through a piece of software called a Web Browser. The collection of all Websites is known as The World Wide Web (or just The Web for short).
Right now, you are reading a Webpage on my Website through your Web Browser. In the "Address Bar" of the Web Browser, it should read https://letslearntogether.neocities.org/ instead of the IP Address of the Server on which these files are contained. This is called a Domain Name. A collection of Servers known as the Domain Name System (or DNS) work together to allow one to type in words instead of IP Addresses in order to find a Website.
The Domain Name and everything after it (in this case, https://letslearntogether.neocities.org/compute/webdev01.html) is called a Uniform Resource Locator (or URL). It points to a specific file within a particular Server. Everything on The Web has a URL.
A Bot (short for "robot") is a computer that runs a program automatically. A Search Engine is a type of Bot that runs a program called a Web Crawler (or Spider). The Spider tries to map out parts of The Web. It does this by visiting Webpages and following as many Hyperlinks as it can, associating each with specific words (called "Keywords"). They are then put into a list called a Search Index.
This Search Index is usually saved to a Server and is accessible to Clients through a Website (e.g.: DuckDuckGo). Type in some Keywords, and it will provide a list of Websites that are related in some way. One can then click on a Hyperlink to visit that Website. Most Search Engines will order that list according to some Algorithm (i.e.: some pattern or set of rules).
All parts of The Web that are mapped out by Search Engines like this are collectively referred to as The Surface Web (or Clearnet). Inversely, the parts that are not mapped out are known as The Deep Web.
How Do We Make Stuff For The Web?
Webpages are written with something known as HyperText Markup Language (or HTML). If we want to make a Website, then we can either:
1. use a Website builder
These generate HTML (e.g.: Sadness' Layout Builder), or help one to lay out a Webpage visually (e.g.: hotglue or mmm.page). These are fairly intuitive to use if you already generally understand how to use a computer, but there are also videos that can guide you through the process.
2. learn how to write HTML
This might sound intimidating, but don't worry! There are a lot of helpful guides out there. There are also free video courses of varying length and complexity (e.g.: BroCode, Traversy Media, freeCodeCamp, etc.).
Generally, the tools that we will use to build a Website are determined by what we want to create. Some common tools are:
| Tool |
Use |
HTML
(HyperText Markup Language) |
creating the underlying structure of a Webpage |
CSS
(Cascading Style Sheet) |
creating the visual layout / design of Websites |
XML
(eXtensible Markup Language) |
creating text data for RSS (Really Simple Syndication), a way of showing "updates" or changes to Websites |
PHP
(Personal Home Page) |
creating Web Applications (i.e.: programs that run on a Server) |
SQL
(Structured Query Language) |
creating Databases, or sets of data, for use by Web Applications |
Some of these are considered "Programming Languages" in their own right, while others are not. There are plenty of excellent resources for learning these in-depth (e.g.: HTML Dog, W3Schools, MDN Web Docs, The Odin Project, Eli the Computer Guy's Introduction to PHP, etc.).
To reiterate, not all of this is necessary to know if we only want a simple Website. All that we need is a little of knowledge of HTML...
HTML is composed of "Tags", strings of characters that tell the Web Browser how to display a Webpage. They are fairly intuitive to understand as many of them are words or acronyms. One can go far just by learning a small handful of HTML Tags. We can create a Webpage by writing some of these Tags along with some text inside of a text document, and then saving it with the file extension .html. These HTML files can be viewed by opening them up with a Web Browser.
HTML is often used in combination with CSS. Instead of using Tags within CSS, we use slightly longer "Rulesets". But they function in a similar way, and again, learning a little bit goes a long way. Rulesets can be used within an HTML file directly. This is known as "Internal CSS". A collection of Rulesets can also be saved as a separate text document with the file extension .css. Multiple HTML files can then refer to the same CSS file. This is known as "External CSS". It allows us to quickly and easily change the design of many Webpages simultaneously. In other words, by changing one CSS file, all of the HTML files that point to it will change in response.
There are a lot of free resources that have material for decorating our Webpages (like background images, fonts, and cursors). If we don't know how to write the HTML Tags or CSS Rulesets to use them, we can probably find whatever we need by asking a Search Engine. For example, "HTML - How do I add a font to a webpage?" or "CSS - How do I set a custom cursor?"
If we want to get extra fancy, we can try "Frameworks" like Bootstrap or Tailwind. These are ways of using CSS to make Webpage designs that are "responsive" (i.e.: they display differently depending on the device that they are viewed with). For example, many Websites look different when viewed on a "smartphone" versus a "desktop" computer.
There is a bit of a learning curve to using a Framework instead of basic HTML and CSS. However, some of the above links have tutorials (like this one on Bootstrap from W3Schools), and more can be easily found through a Search Engine (like this one on Tailwind from CodeinWP).
What Do We Do With These Files?
The files that we make with all of these tools must be saved (or "Hosted") on a Server so that Clients all over The Internet can access them. Self-Hosting is when:
1. We rent access to a computer that we use as a Server
2. We own and operate the computer that is acting as a Server
There are also Hosting Services (like Neocities, Angelfire, NekoWeb, Ichi City, Web 1.0 Hosting, and others) that are limited in the types of files that they will Host and what we can do on that Server. They are usually good for simple Websites.

How Do We Rent A Server?
Some companies have large computers that are programmed to be like many Servers running in parallel. Each of these is called a Virtual Private Server (or VPS). We can rent one of these to Host our files. LandChad is a good resource for learning how to do this. [Thanks to nekobusses for this last link!]
How Do We Build & Maintain A Server?
We can go one step further and build a Server. This might seem like a complicated and expensive process, but it doesn't have to be! Many people who have set up their own Servers are willing to share their experiences too.
In essence, it just requires that we install some Server software on a computer that is connected to The Internet. There are a couple of considerations when it comes to the hardware used within that computer too, such as:
1. Hard Drives
The lifespan of Hard Drives is determined not only by how long we've had it, but also by how much data we put onto it and how many times that it is erased. This is called a Program / Erase Cycle (or P / E for short).
Sometimes when we buy a Hard Drive it will have a P / E measurement. One can buy Hard Drives for specific uses that will have a higher rating. For example, there are so-called "enterprise grade" Hard Drives for use in Servers. We need a reliable Hard Drive within a Server because the information on them will probably be accessed a lot!
In the case of Solid State Drives (or SSDs), it is good to leave about 10% of the drive space free. Filling it to maximum capacity shortens its lifespan. On average, one can expect a Hard Drive to last 3-5 years.
BackBlaze does studies showing the long-term reliability of various Hard Drive models. Recovery of data from a failed Hard Drive can be very expensive and is hit-or-miss depending on how that data was lost.
If we are in a situation where we need to regularly backup a lot of data, we could try setting up a Redundant Array of Independent Disks (or RAID). This is a system that automatically distributes data across multiple Hard Drives, so that if one fails, we can still recover all of the data.
Whether using one Hard Drive or many, there are programs that will periodically make a backup of their contents in case something goes awry. Part of using a Hard Drive effectively is learning how this type of software works. Usually it is straightforward process. It may consist of setting a time and date for when we want those backups to be made, and then choosing some options on how detailed we want those backups to be.
We may not care about all of the information on a Hard Drive, but some files are critical for keeping things working.
2. Power Supplies
Servers can experience "downtime" when something keeps it from functioning normally. This includes loss of power. There is a special type of computer Power Supply that has a rechargable battery as a backup source of power. It is called an Uninterruptible Power Supply (or UPS).
A UPS can vary in:
• The total amount of its electrical input and output
Different types of devices can require differing amounts of electricity.
• The number of outlets it has, and whether or not they have Automatic Voltage Regulation (or AVR)
This allows each device to get the appropriate amount of electricity.
• How long its internal batteries last and how long they take to recharge
A battery that can last longer can survive a longer power outage.
• Other features (e.g.: LCD control panels, extra USB ports, and so on)
These are optional and usually included as a matter of convenience.
Again, none of this has to be complicated or expensive. Depending upon what we are Self-Hosting, it could be as simple as getting a Single Board Computer (or SBC) like a Raspberry Pi, and connecting it to a power source and The Internet. If we don't mind "downtime", the power source doesn't even have to be consistent. A really interesting example is Low-Tech Magazine's solar powered website.
There are a few considerations about security that must be addressed when running a Server as well, but we will cover those later. For now, let's look at what we can do if we have full access to both a Server and a Client...
What Can We Do With A Server & A Client?
Web Applications are programs that are run on a Server, but are controlled by a Client through their Web Browser. We could design Web Applications for a variety of different purposes instead of looking for services on The Internet that will do those tasks for us. If we store these programs on a Server, then we can share them with whomever we want, or access them from another computer whenever we are located far away from it. The tools that we can use when creating things and our options for connecting with others increases dramatically.
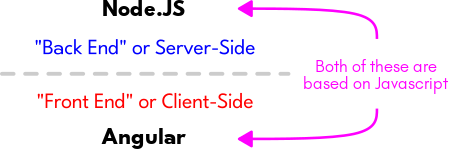
For example, Javascript is perhaps the most common Programming Language for making Webpages that are interactive in some way. In this capacity, its use is taking place within the Web Browser of the Client. However, we can also run Javascript on the Server itself. One method of doing this is by combining a "Runtime Environment" (such as Node.JS) and a "Framework" (such as Angular):
This allows us to use the same Programming Language for designing what someone sees and interacts with when they visit a Website (i.e.: the "Front-End") and for the logical infrastructure that is running in the background, what the Website is built upon (i.e.: the "Back-End").
In summary, the Front-End is what happens on the Client and the Back-End is what happens on the Server. They have to work together for anything to happen on The Web!
If we are using HTML and CSS, then we are already doing "Front-End Development" to some extent. The Front-End is primarily concerned with "User Experience" and the "User Interface" (shortened to UX / UI). This is all of the stuff that is normally handled during the visual design of a Webpage (e.g.: colors, fonts, etc.). It includes more subtle considerations about interaction as well, like Accessibility (i.e.: designing things to be easy for people with many different needs to use them).
If one wants to create things to be Accessible, there are guidelines for websites and other communication mediums. Pixel Glade's Accessibility Resources is a fantastic page for learning more.
...But what is "Back-End Development"?
Many Webpages are "static" in that they only display information. They are not interactive or "dynamic". Sometimes when we interact with a dynamic Webpage, the data that is generated must be stored within a Database for future reference. When it is needed again, the data is called forth from the Database through a Query Language. One of the most well-known is Structured Query Language (or SQL). This data might also be shuttled around between multiple programs connected together through an Application Programming Interface (or API) to create some sort of result. This result may then be sent back to the Web Browser of the Client to be displayed. All of these types of activities happen within the Back-End.
Front-End Development is a different set of skills from Back-End Development, but they both complement each other. In the most general sense, Software Development is synonymous with programming. When we can write programs for both Clients and Servers (i.e.: for both Front-End and Back-End purposes), then we are doing Full-Stack Development. The "Stack" refers to all of the hardware and software that make up the Client and Server (including the Operating Systems that they are using).
roadmap.sh has step-by-step guides for gaining an understanding of Full-Stack Development and many related subjects.
What Is Cybersecurity?
While these terms are often confused for one another, there is a difference between "Anonymity", "Privacy", and "Security". To loosely paraphrase Privacy Guides:
• Anonymity is when information is not connected to an identity.
• Privacy is making sure that information is only shared with who we intend to share it with.
• Security is the ability to trust the systems that we use to communicate information. "Cybersecurity" deals specifcially with computer systems.
Rather than review various tools (like on Restore Privacy or ProPrivacy), we will attempt to give some concepts and practices for understanding and implementing Cybersecurity.
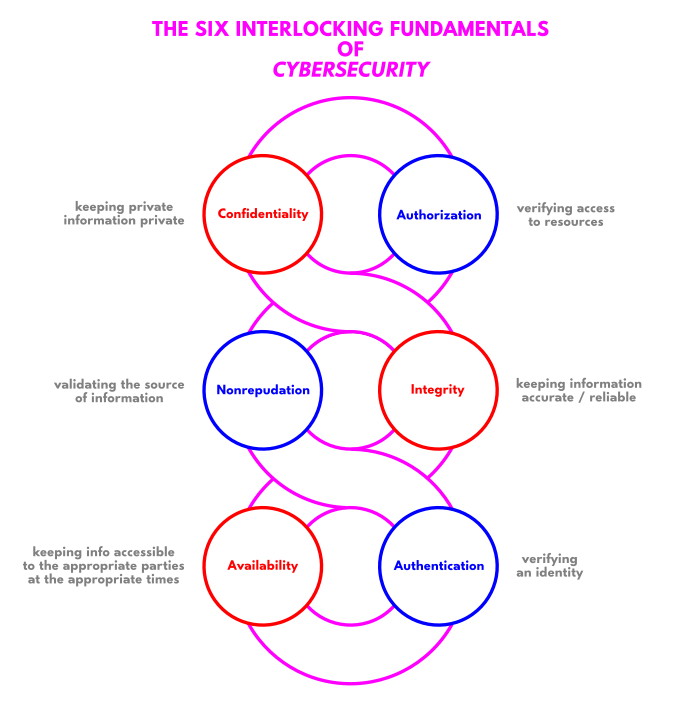
Let's start with a general model that we will call, "The Cybersecurity Chain":
There is a common saying: "A chain is only as strong as its weakest link."
In other words, if any link within a chain breaks, then the whole chain falls apart. Likewise, if any one of the things represented by the six circles in the above diagram is compromised, then that system is "insecure".
Notice how the red circles and the blue circles that are directly across from one another complement each other. For example, for there to be Integrity (i.e.: accurate and reliable information), there must also be Nonrepudation (i.e.: verifying the source of information). Each implies the other. Oftentimes, these blue circles are forgotten as people focus entirely on the red circles. The red circles are collectively referred to as The CIA Triad (after the first letter of the words Confidentiality, Integrity, and Availability).
As we continue, the meaning of this model will become more clear.
Safety In Web Surfing
Learning how to use The Internet safely is not just for children. The Center for Cybersecurity Innovation & Outreach has a series of videos that can give one a good foundation. They are based on the book Computer Security Literacy: Staying Safe In A Digital World by Douglas Jacobson & Joseph Idziorek.
• Basics of Cryptography, HTTPS/TLS/SSL Encryption
• Cookies
• Passwords & Entropy
• Malware/Spyware (Viruses, Worms, Trojans, Keyloggers, etc.)
• Firewalls, Packet Sniffing / Wardriving
• Proxies, Virtual Private Networks (VPNs), Tor & The Dark Web
• Email (Spam Filtering, PGP Encryption)
• Phishing Scams, Spoofing, Social Engineering
• Cyberbullying, Doxxing, Identity Theft, Swatting
Protecting Our Personal Website
• Using a robot.txt, Blocking A Spider
• Handling Guestbook Spam
Running Our Own Social Network?
• Getting Started, Community Moderation
• Hacking, Hats (Black, White, Grey), Pentesting
• Vulnerabilities, Countermeasures, Patch Management, Attack Surface
• Threat Assessment, NIST Framework, CMMC Implementation, etc.
[In Progress...]